勤務校でSurface Pro 10が支給されました。Core Ultraを搭載した2024年モデルの2 in 1タブレット端末です。キャッチコピーは「AI を搭載したポータブルな法人向けタブレット」です。
ただ、普通に使っている分には搭載されているAIを使いこなしていることを感じることがありません。2024年10月23日記事執筆時点ではCopilotはβ版ですし、ローカルで動いていません。Intel AI Boost NPUが搭載されているので「AI搭載」と表現されているわけですが、使わないと意味がありません。
というわけで今回はSurface Pro 10のIntel NPUのリソースを使ってローカルでLLMを動かしてみました。
実行環境の用意
Miniconda3のインストール
まずは環境を整えます。Pythonで動かすのでMiniconda3をインストールしました。
Miniconda — Anaconda documentation
Miniconda3-latest-Windows-x86_64.exeを実行して、ひとまずPython3が動く環境を用意しました。
Intel NPUのデバイスドライバを更新する
Surface Pro 10の出荷時にインストールされているNPUドライバではLLM実行時にエラーが出ました。なのでまずはIntelのサイトより最新版のデバイスドライバをダウンロードしてデバイスドライバより手動で更新します。 https://downloadmirror.intel.com/825735/NPU_Win_Release_Notes_v2540.pdf
仮想環境を整える
Pythonの開発環境を整える際は、用途に応じてバージョンなどに気をつけるため仮想環境を用意するそうです。Miniconda3(Anaconda3も同じ)のcondaコマンドでLLM用の仮想環境を作ります。
conda create -n llm python=3.10.6
多分バージョン3.11以降でも動きそうですが、参考にしたサイトがこのバージョンで環境を構築していたのでひとまずこのバージョンにしました。
conda activate llm
環境が用意できたら有効化しておきます。そのあとで、Intel NPUを扱うためのライブラリをインストールします。
pip install torch
pip install intel_npu_acceleration_library
参考にしたサイトはこちらです。 【西川和久の不定期コラム】Core UltraにせっかくNPUが付いてるのでLLMや画像生成を動かしてみた!ミニPC「UH125 Pro」で - PC Watch
ライブラリの一部を修正する
記事執筆時点でのintel_npu_acceleration_libraryをそのまま使おうとすると、推論時にエラーが出ました。なのでこちらの記事を参考に修正します。
Intel® NPU Acceleration Library を使って LocalLLM を Intel NPU で動かす #Python - Qiita
ただGithubを見る限りプルリクは通っている気がするので、恐らく次に公開されるバージョン以降では修正されていると思います。(参照元のサイトにもこのような記述がありましたが、まだアップデートされておらず、僕自身も手動で修正しました。)
ちなみにMiniconda3のcondaコマンドで作った仮想環境でpipすると、修正対象のllm.pyはこのパスにありました。
C:\Users\ユーザー名\AppData\Local\miniconda3\envs\llm\Lib\site-packages\intel_npu_acceleration_library\nn\llm.py
LLMのモデルをローカルにダウンロードしておく
本来ならプログラムの初回実行時にモデルをダウンロードする内容がソースコードに書かれているんですが、僕の環境ではうまく動かなかったので、実行前にLLMのモデルをダウンロードしておきました。
今回の動作検証に使ったモデルは「TinyLlama/TinyLlama-1.1B-Chat-v1.0」です。
僕の場合はこちらの場所にフォルダを作りました。
C:\Users\ユーザー名\models\tinyllama
Hugging Faceにて公開されているファイルを一通り上記フォルダにダウンロードして保存しておきます。
TinyLlama/TinyLlama-1.1B-Chat-v1.0 at main
実際に推論させてみる
今回動かしたプログラムのソースコードはこちらです。
from torch.profiler import profile, ProfilerActivity
from transformers import AutoTokenizer, TextStreamer, AutoModelForCausalLM
from threading import Thread
import intel_npu_acceleration_library
import torch
import time
import sys
import os
# SSL検証を無効化
os.environ['CURL_CA_BUNDLE'] = ''
os.environ['REQUESTS_CA_BUNDLE'] = ''
# モデルIDを使用
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
# モデルのローカルパス
local_model_path = "./models/tinyllama"
# モデルをロード(公式コードにより近い形で)
model = AutoModelForCausalLM.from_pretrained(
local_model_path, # ローカルパスを使用
local_files_only=True,
use_cache=True
).eval()
tokenizer = AutoTokenizer.from_pretrained(
local_model_path, # ローカルパスを使用
local_files_only=True,
use_default_system_prompt=True
)
tokenizer.pad_token_id = tokenizer.eos_token_id
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
print("Compile model for the NPU")
model = intel_npu_acceleration_library.compile(model)
print("モデルのコンパイルが成功しました")
query = "What is the meaning of life?"
prefix = tokenizer(query, return_tensors="pt")["input_ids"]
generation_kwargs = dict(
input_ids=prefix,
streamer=streamer,
do_sample=True,
top_k=50,
top_p=0.9,
)
print("Run inference")
try:
_ = model.generate(**generation_kwargs)
except Exception as e:
print(f"推論エラー: {str(e)}")
import traceback
print("\nエラーの詳細:")
print(traceback.format_exc())
元ネタはIntel NPU Acceleration Libraryにあったサンプルですが、LLMをローカルから参照するように変更してあります。
Large Language models — Intel® NPU Acceleration Library documentation
実際に推論している様子がこちらです。
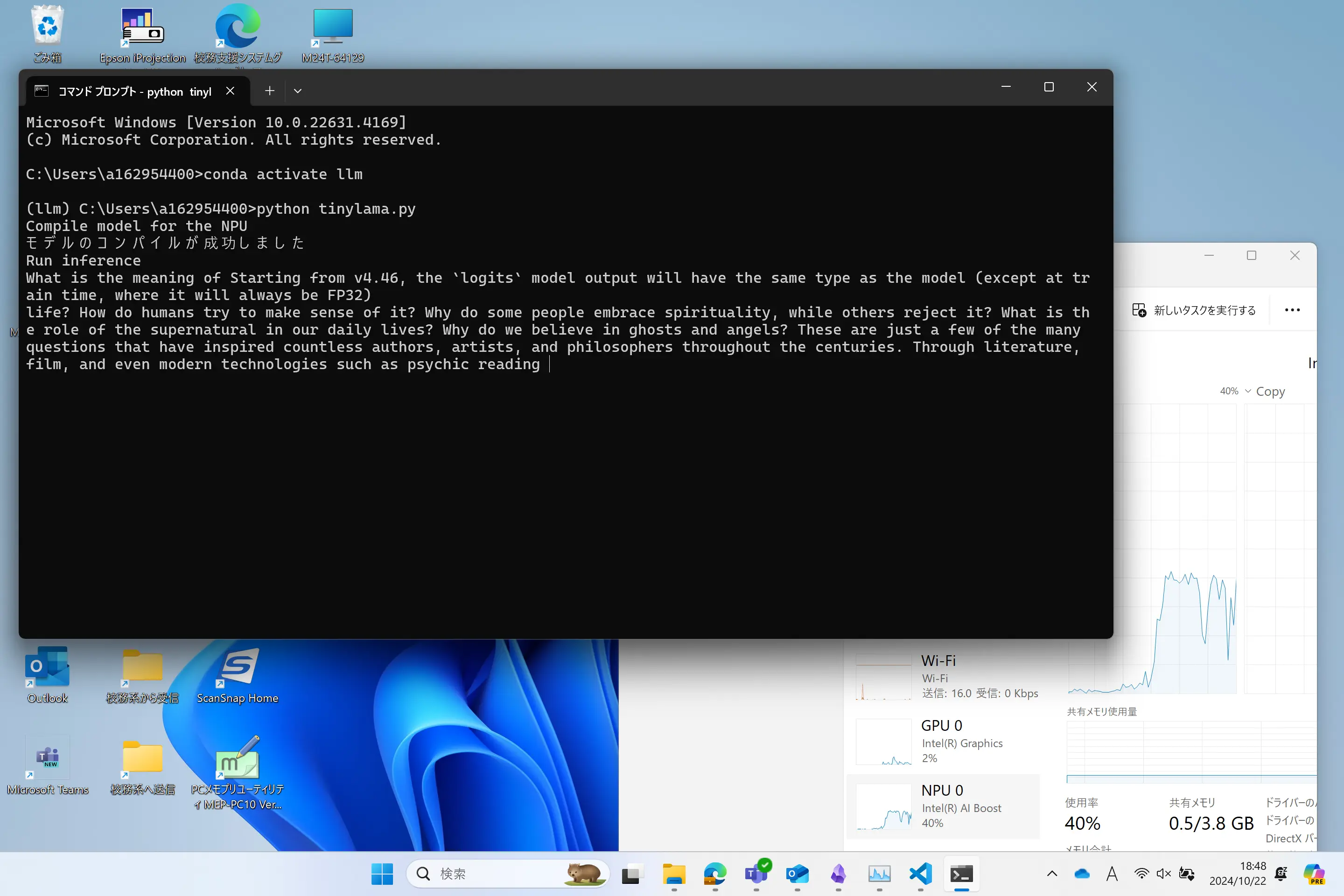
タスクマネージャーを見てみるとNPUの使用率が上がっていることが確認できました。最大で約40%ほど使っていました。ただCPUがずっと100%に張り付いていて、他の作業ができなくなるほどでした。
というか支給されたSurface Pro 10はメモリ8GBでSSD256GB。これでローカルLLMが動いているのも信じられないです。動作はかなり遅いんですけどね。英単語が出てくるごとに感動を覚えます。全然実用的ではありませんけどね。
使い勝手なんて話し出したらChatGPTの方が使いやすいのは当然です。ただ今回は、せっかくNPUを搭載しているんだから、使ってみないとなという好奇心から動作検証に至りました。現時点では全然実用的ではありませんが「先生のタブレット、AI入ってるんだー」なんて言いながら、子どもたちに見せようかな。
